Researchers at the Barcelona Supercomputing Center (BSC) publish a first model of a large open source language (LLM), licensed for both research and commercial use called “Âguila” . It is a 7B-parameter LLM consisting of 26 billion Spanish, Catalan and English data tiles based on falcon-7b , a state-of-the-art English language model that was openly released just a few months ago. All this information allows the model to develop complex tasks such as writing and sending emails from scratch or suggesting a response to start speaking in everyday conversations following human behavioral patterns. These preliminary experiments demonstrate that the Âguila model has proven to have some impressive capabilities.
BSC experts expect that most of the acquired knowledge will be retained in other pre-trained checkpoints that will allow knowledge transfer between languages and greatly reduce the cost of training an optimal chinchilla model in a short time. BSC researchers came up with the idea of using an English LLM as a starting point to form a model for Catalan and Spanish. Specifically, they adapted the model[falcon-7b] ( https://huggingface.co/tiiuae/falcon-7b ) for these two languages by swapping the tokenizer and adjusting the embedding layer. “The main motivation is to take advantage of the knowledge acquired by Falcon from a large amount of data in English and transfer it to other target languages” , says Marta Villegas, BSC team leader of the Language Technologies unit . The training is composed of 26B files that include data in Spanish and Catalan in equal proportion (approximately 40% each) and a smaller amount of data in English (~17%). Preliminary experiments with Âguila show some impressive capabilities as seen in the following example that shows the model’s behavior in a sparse environment:
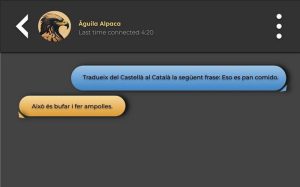
Âguila is based on the Falcon-7b model, which is a state-of-the-art English language model recently made available by the Institute of Technological Innovation.
So far, BSC researchers have only conducted a small-scale qualitative study, but they intend to conduct a comprehensive human evaluation and collect results from experiments with zero and few results on standard benchmarks in the near future. BSC researchers are working on aligning the model using a corpus of instructions in English, Spanish and Catalan.
Project Aina | Communication and press
press.languagetech@bsc.es

